How to generate and detect phishing domains with Internationalized Domain Name homograph attacks.
Internationalized Domain Names are domain names with Unicode characters from a wide number of languages which make the Internet more accessible for non-English speakers. These domain names can be abused for phishing by impersonating other websites or brands by using Unicode characters that resemble Latin letters.
In this post, we take a look at how to generate and detect phishing domains with Internationalized Domain Names, what homograph attacks are, how they can be carried out, and how to detect them.
What is typosquatting?
Typosquatting, otherwise known as URL hijacking or brandjacking, is a tactic traditionally used by cyber threat actors to register domain names that resemble popular or legitimate websites or brands. This tactic takes advantage of:
- users’ typing errors (or typos) when entering URLs into their web browsers
- domains that are visually similar to impersonated brands or websites
These domains often lead to websites that imitate the design or content of the impersonated websites or brands to deceive users for several reasons, one of them being to carry out phishing. For example, to impersonate this blog, a malicious actor might register the following domains:
intothethickoff[.]it
iintothethickof[.]it
inintothethickof[.]it
...At first glance, a user might not think that there is anything wrong with the domains above. However, upon closer inspection, we can see that there are misspellings or extra words in the domains. An unaware user might mistype the domain into their web browser, or click on a link to one of the domains above, directing them to a typosquatted website instead of this blog.
With the usage of Internationalized Domain Names, the problem of visually-similar domains is worsened, bringing about a similar issue created by typosquatting. In the subsequent sections, we explore what they are and how they are abused.
Internationalized Domain Names
Internationalized Domain Names (IDNs) were introduced to allow domains with non-ASCII characters, making the Internet more accessible to non-English speakers by facilitating the use of local languages in domains. If you are interested, you can read more about IDN history on ICANNWiki, the Wikipedia page of IDNs, or in these infographics by ICANN.
Without diving into too much into its history, IDNs allow users to access websites via domains such as:
គេហទំព័រដុតនំអនឡាញ[.]com
нефонтанка[.]рф
ネットショップ制作[.]com
fogadási-oldalak[.]com
虎丫炒鸡[.]com
délecté[.]com
...Homograph attacks in ASCII and IDNs
Malicious actors could conduct homograph attacks by registering domains that are visually-similar to a website or brand they wanted to impersonate. For example, to impersonate Microsoft, they would register “rnicrosoft[.]com”, where “rn” could be confused for “m” in “microsoft[.]com”.
This attack vector is greatly improved by conducting homograph attacks on IDNs due to the introduction of different languages that have a vast number of visually-similar characters to Latin letters. Homograph attacks on IDNs go beyond just misspellings and can be performed with domains that are almost visually-indistinguishable from impersonated websites or brands.
Take a look at some examples of IDN domains below that impersonate some well-known brands by using Cyrillic letters instead of Latin letters:
wikipediа[.]org -> Cyrillic letter "а"
аpple[.]com -> Cyrillic letter "а"
fасebook[.]com -> Cyrillic letters "а" and "с"
...Thankfully, to distinguish IDNs from ASCII domains, they must be registered with the “xn--” prefix, called the ASCII Compatible Encoding (ACE) prefix. This means that the example above, “wikipediа[.]org”, is registered as “xn--wikipedi-86g[.]org“. The encoding format used to represent IDNs with ASCII characters is called punycode.
Today, most modern web browsers will detect IDNs in URLs entered by users and automatically convert them to punycode, providing a level of protection for users. For example, the IDN “fасebook[.]com” from above is converted to its punycode representation “xn--febook-3nf0l[.]com” in my mobile device’s web browser:
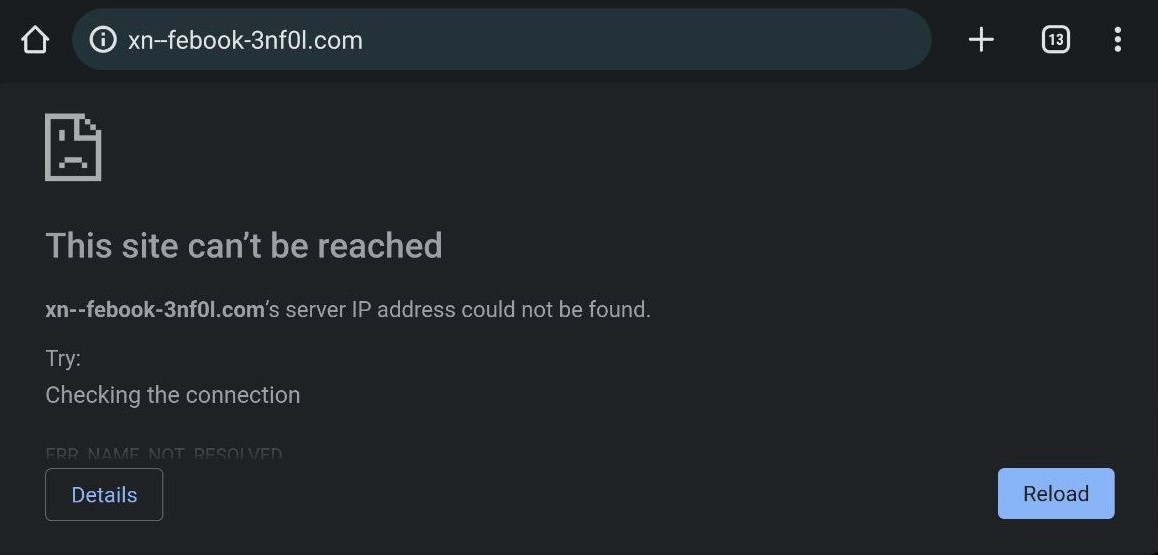
Finding visually-similar Latin letters
On 26 August 2022, the Unicode Consortium published Unicode Technical Standards #39 (UTS #39), detailing mechanisms used in detecting and avoiding security problems connected with the use of Unicode. Along with UTS #39, they published Version 15.0.0 of confusables.txt, a document containing mappings for “visual confusables for use in detecting possible security problems“.
In gist, the document contains all Unicode characters that are visually similar to Latin letters, and other characters allowed for use in IDN domains.

This document lists more than 480 possible Unicode characters that are visually-similar to Latin letters which can be used to perform homograph attacks.
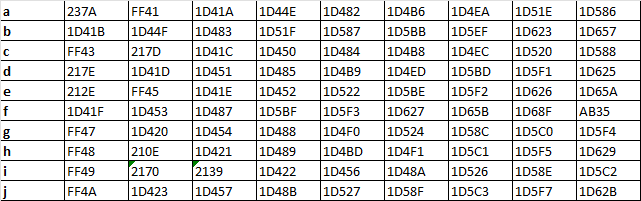
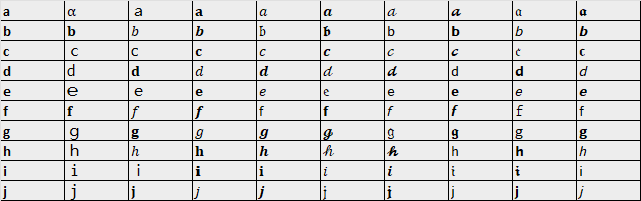
However, not all of the 480 Unicode characters can be used in IDNs. By testing which characters are allowed, and only choosing characters that I feel are visually-similar, we are left with a list that looks closer to this:

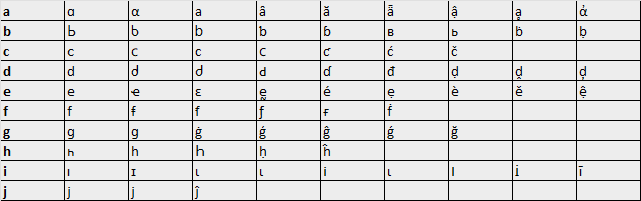
After refining our list, we are left with 303 Unicode characters that we can use to impersonate Latin letters. Remember, the concept of visually-similar characters is subjective and will vary from person to person – the list above is non-exhaustive and can be adjusted.
Automating IDN homograph attacks
With the list we generated above, we create our own dictionary of “confusables” to be used in automating IDN homograph attacks. I then wrote a script which accepts Latin letters as input and outputs possible IDNs using our confusables dictionary.
Let’s start by impersonating the Web-based version of the messaging app Telegram (telegram[.]org). Based on our dictionary, there are 1375920000 (1.3 billion!) possible combinations for “telegram”. This is calculated by multiplying the number of possibilities for each character in the input string (9*25*13*25*8*12*28*7).

Even after refining our list, we quickly find that some characters combinations are incompatible in an IDN (due of restrictions that control the usage of left-to-right or right-to-left characters). This means that the actual number of possibilities would be a quite far away from 1375920000. Instead of generating the full list of possibilities (which would take ages to complete), see below for a snippet of the results instead.
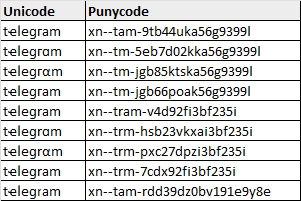
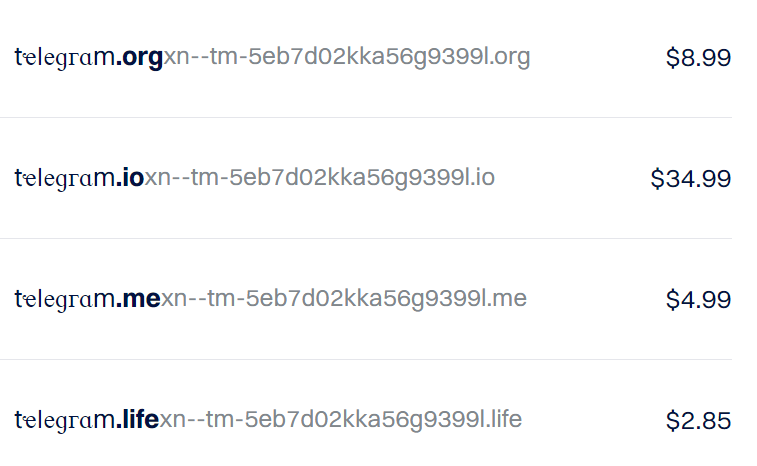
Using domain name registrars such as Dynadot, we verify that our IDN homographs can indeed be registered:
Detecting IDN homograph attacks
Now that we are able to automate IDN homograph attacks, how about the opposite? Well, since we already have our own dictionary of confusables, we can repurpose it to detect IDN homograph attacks.
One method of detecting IDN homograph attacks is to convert each Unicode character in an IDN to its Latin letter-lookalike, then matching the resulting domain to a list of keywords we would like to detect.
To test this detection method, we start with a list of newly registered domains over the past 2-3 months. For this post, I am using a list of newly registered domains obtained from WhoisDS. WhoisDS provides a free service where users can download a list of 100 thousand newly registered domains everyday.
In total, our list consists of roughly 7.8 million domains. After separating the IDNs from regular domains, we are left with about 38 thousand IDNs to analyse.
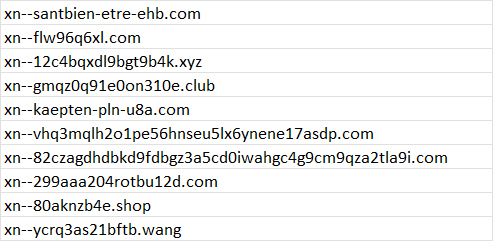
To obtain a list of keywords we want to detect, we download a list of the most-visited websites worldwide from Majestic (rip Alexa) and retrieve the top 10000 domains in the world. After removing duplicates and subdomains, we are left with about ~8900 keywords to monitor. We use this list of keywords as they are more likely to be targeted, but they can be whatever you feel like monitoring.

For each IDN, we iterate through each character in the IDN and attempt to match it to the Latin letter from our confusables dictionary, using a sort-of “reverse-lookup” method. The matching Latin letters are used to build a string that we match against the list of keywords that we specified. Using this method, we detected a decent number of IDNs that could have been registered to perform homograph attacks!
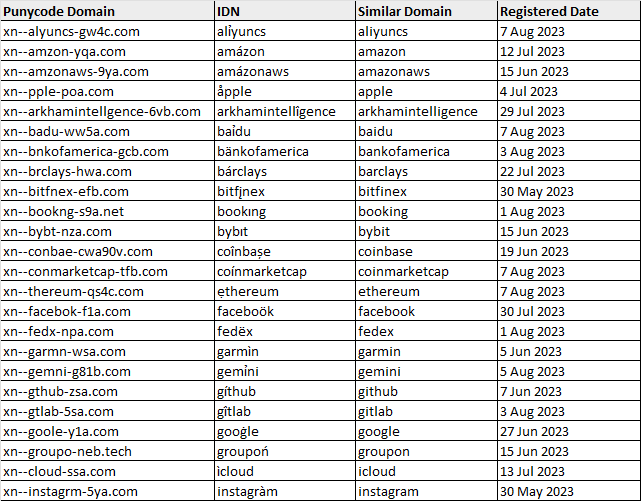
As seen from the image above, there are some suspicious newly registered IDNs that are visually-similar to popular websites. These popular websites span across several categories, such as e-commerce, social media, finance, and delivery services, among other things. We do not know exactly what these IDNs were registered for, but I’d wager that a few of them are for malicious purposes.
For example, looking at arkhamintellîgence[.]com (xn--arkhamintellgence-6vb[.]com), we see a site that looks identical to the website of the blockchain intelligence platform Arkham Intelligence (arkhamintelligence[.]com).
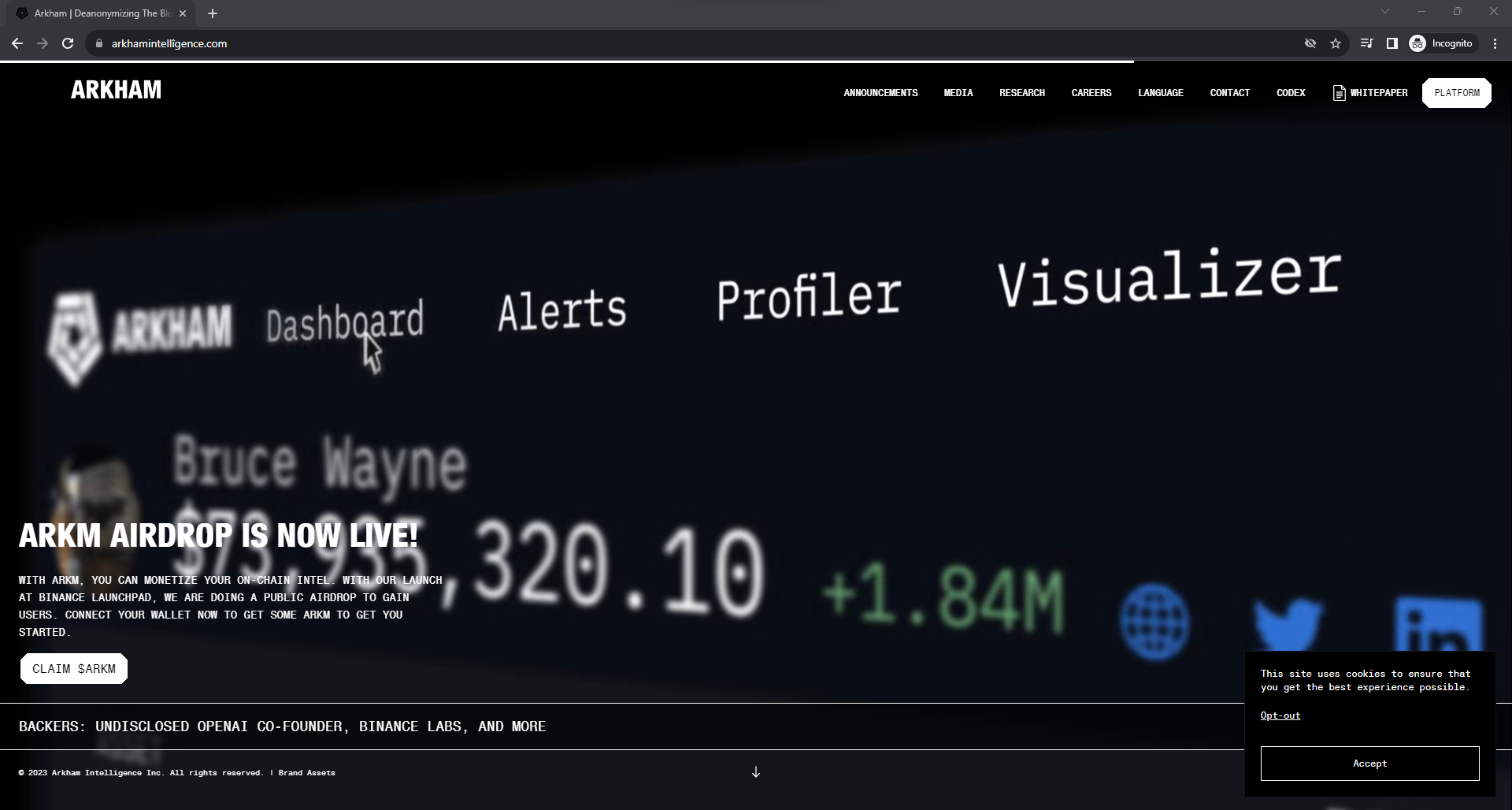
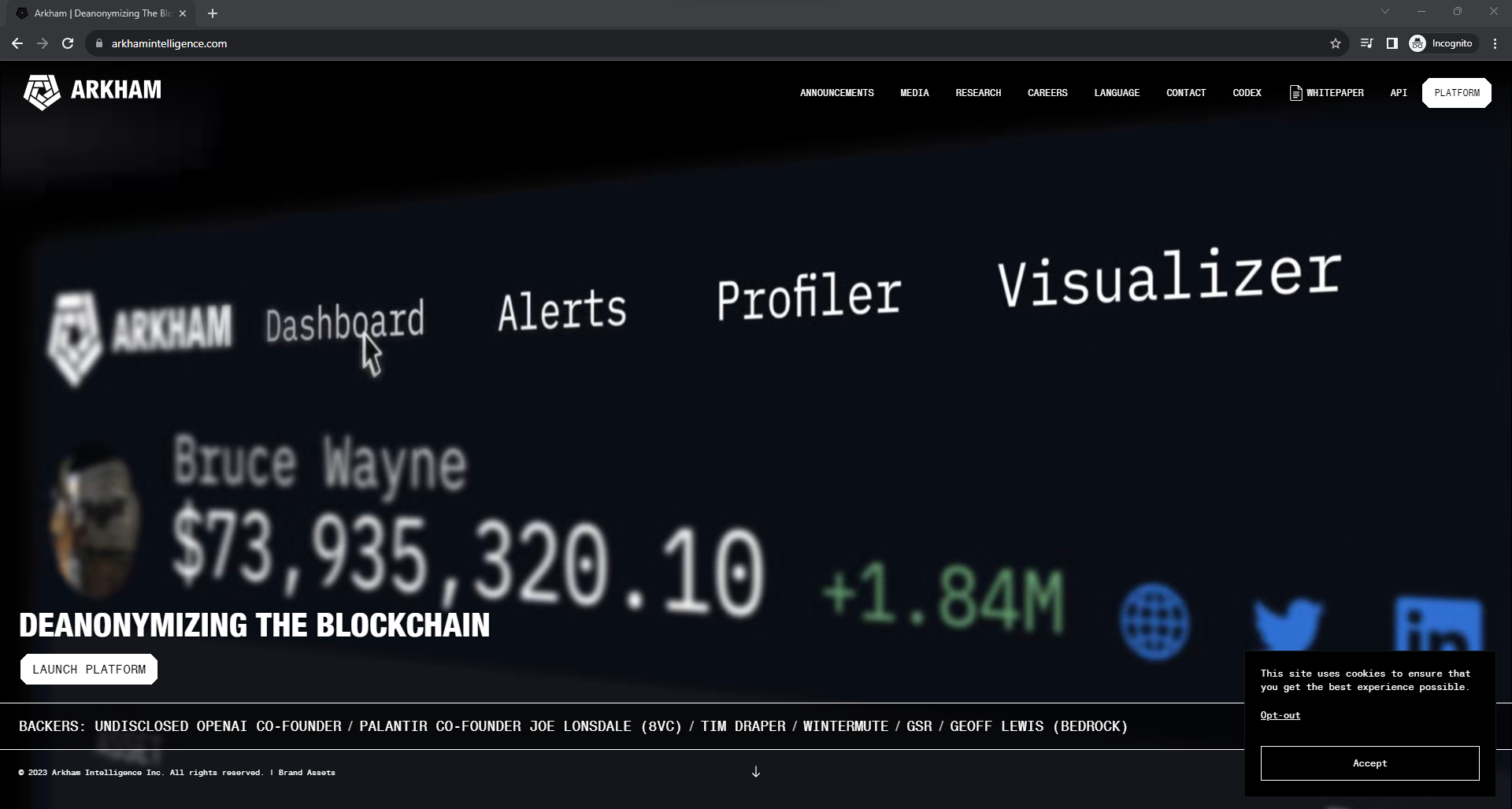
The only visible difference between the two sites is that arkhamintellîgence[.]com prompts users to link their crypto wallet to the site for a cryptocurrency airdrop event which, in my opinion, is suspicious to say the least.
In total, we detected 266 IDNs that were possibly registered for malicious purposes over a 2-3 month period. This figure will vary depending on:
- the number of keywords monitored
- the comprehensiveness of the newly registered domains dataset
- the dictionary of confusables and impersonated characters
Final Words
As shown in the post, it is trivial for bad actors to generate these homograph attacks on IDNs with automation. When browsing the internet, users should keep an eye out for such homograph attacks by being wary of the links they click and websites they visit. On the other hand, it is possible for defenders to use the proposed detection method to discover these domains before any harm is done.
The scripts, dictionary, and monitored keywords have been released on GitHub and you can find them here. Until next time, happy hunting!

Leave a comment